Tutorial y código por pybonacci.
Los bots, ¿qué decir de los bots? Pues tengo que confesar que, en general, los detesto. Y, ¿por qué? Porque la inmensa mayoría suelen ser molestos y te hacen perder el tiempo. Pero, por supuesto, vamos a hacer un bot que sea útil. Si no tienes pensado hacer un bot que haga algo útil para otras personas, si vas a mandar SPAM, publicidad, etcétera, por favor, no sigas leyendo y cambia de idea.
¿Qué hara nuestro bot?
Vamos a aprovechar que arXiv.org dispone de una API. Para el que no lo sepa, arXiv es un repositorio de pre-prints o prepublicaciones. Vale, y ¿qué es un pre-print? Es un artículo científico que aun no ha sido revisado por pares. Digamos que es un artículo científico en bruto.
Nuestro bot visitará la API de arXiv y recolectará las nuevas prepublicaciones de una temática en concreto. Las temáticas de las prepublicaciones las podéis ver en este enlace. La que he elegido será la temática physics.ao-ph relacionada con física de la atmósfera y del océano.
Una vez que tengamos las nuevas prepublicaciones crearemos un toot (es un tuit pero en mastodóntico) por cada una de ellas usando la API de Mastodon y lo publicaremos en una cuenta que habremos creado para nuestro bot.
Cuenta para hospedar nuestro bot
Para el que no lo sepa, Mastodon es una red social similar a tuiter pero es de código abierto y federada. Lo primero significa que puedes tener tu propio Mastodon, si quieres, o puedes unirte a una de las múltiples instancias que hay. Que sea federada significa que puedes seguir cuentas de otras instancias ya que las diferentes instancias se comunican entre sí usando ActivityPub. La federación no se consigue solo con Mastodon, hay muchas otras opciones de poder seguir a gente en otro tipo de redes sociales como PixelFed (similar a Instagram), Pleroma (similar a FB),… Estas redes federadas es lo que se conoce como Fediverso.
Dentro de las instancias de Mastodon tenemos la instancia botsin.space. Esta instancia está especializada en bots así que es ideal para lo que queremos. Tenemos que crearnos una cuenta nueva. En mi caso la he llamado aosbot. Lo podemos hacer rellenando el formulario:
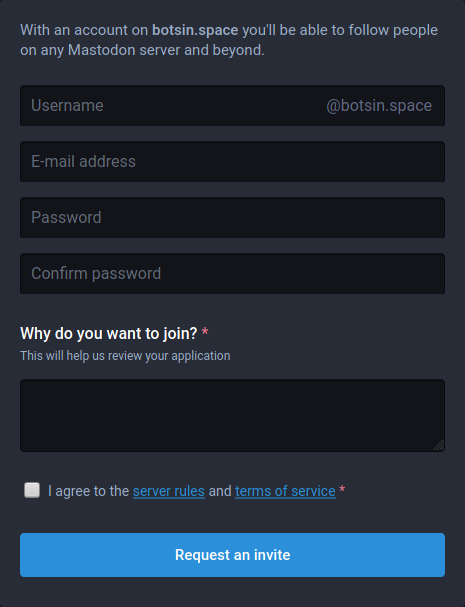
El administrador de la instancia nos tiene que aprobar primero la cuenta. En el momento que esté aprobada podemos ajustar varias cosas como la imagen de la cuenta, la imagen del cabecero, etc. Es importante que le déis OK a la pestaña que indica que la cuenta es un bot:
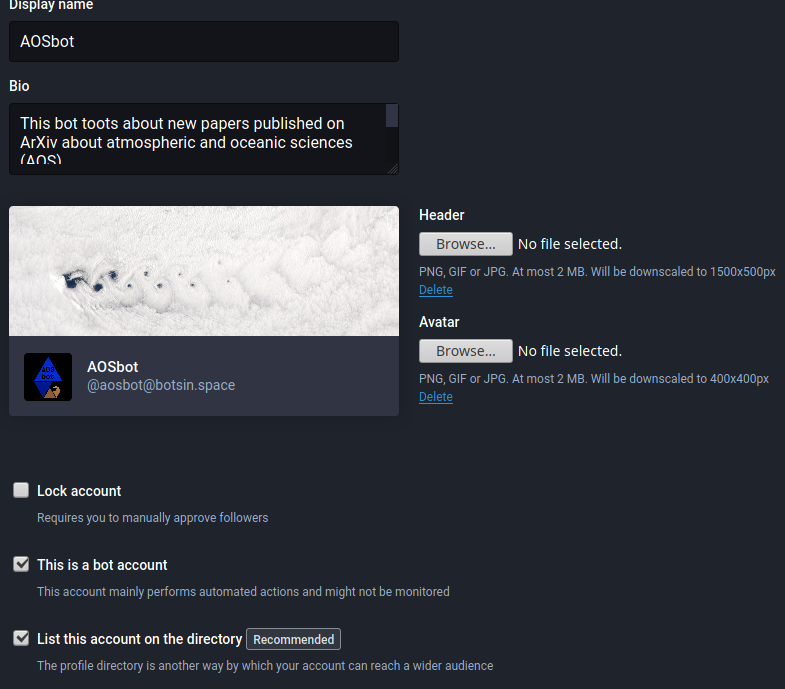
Para poder escribir en la cuenta usando la API de Mastodon tendremos que ir a la opción development de nuestro profile y allí pinchar sobre el botón para crear una nueva aplicación:
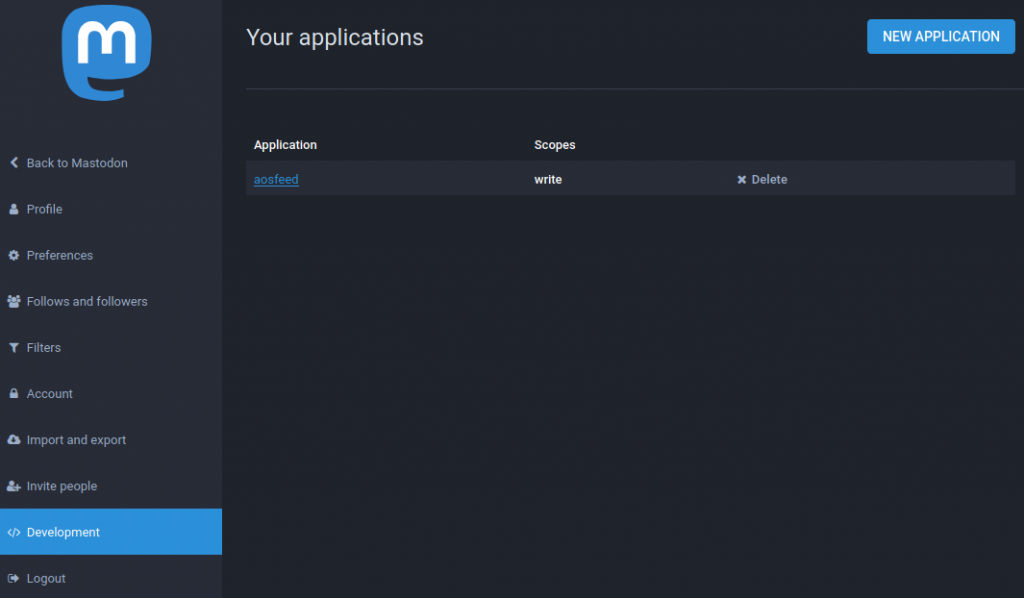
En la imagen de arriba véis que ya hay una aplicación que se llama aosfeed. Cuando creéis vuestra propia aplicación rellenad lo que os pida en los permisos (scopes) seleccionad permisos de escritura (write). Para lo que vamos a hacer basta con que este permiso esté activado y el resto desactivados:
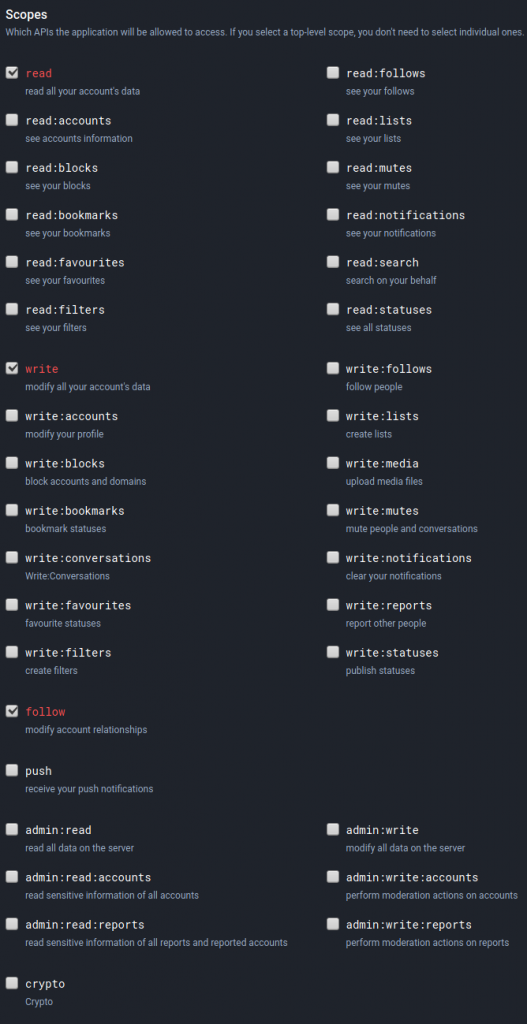
Una vez que hayáis creado la nueva aplicación, si pulsáis sobre la misma (desde la sección development) veréis un área que nos da una serie de información:

Lo que usarémos en nuestro bot será el access token.
Y llegamos al código Python que hará la magia.
Para hacer el bot solo voy a usar Python y la stdlib para que sea sencillo ejecutarlo desde casi cualquier sitio que tenga un Python moderno instalado.
El programa python lo tendremos que tener en un sitio que pueda ejecutar python y donde tengamos permisos de escritura.
Tendremos que meterlo en cron para que se ejecute de forma periódica. O ejecutarlo a mano siempre que desees.
El código Python completo será como el siguiente:
from urllib.request import urlopen, Request
from dataclasses import dataclass
from xml.etree import ElementTree
import re
import json
from pathlib import Path
import datetime as dt
@dataclass
class Paper:
title: str
description: str
link: str
creator: str
def _clean_title(self):
return self.title.split("(arXiv:")[0]
def _clean_description(self):
return self.description.replace("<p>", "").replace("</p>", "")
def _clean_creator(self):
reg_str = "<a href=.*?>(.*?)</a>"
res = re.findall(reg_str, self.creator)
return ", ".join(res)
def get_toot_text(self):
part1 = f"Title: {self._clean_title()}\n\n"
part3 = f"Authors: {self._clean_creator()}\n\n"
part4 = f"Link: {self.link}"
length = 500 - len(part1 + part3 + part4)
part2 = f"{self._clean_description()[:length - 8]} [...]\n\n"
toot_text = (part1 + part2 + part3 + part4)
return toot_text
def toot(self):
host = "https://botsin.space/api/v1/statuses"
token = "########TU_TOKEN########"
headers = {}
headers['Authorization'] = 'Bearer ' + token
headers["Content-Type"] = "application/json"
#headers = json.dumps(headers)
data = {}
data['status'] = self.get_toot_text()
data['visibility'] = 'public'
data = json.dumps(data).encode('utf-8')
req = Request(url=host, data=data, headers=headers)
resp = urlopen(req)
return resp.status
older_file = 'older.txt'
older_file_bak = 'older.txt.bak'
ori = Path(__file__).parent.absolute() / older_file
bak = Path(__file__).parent.absolute() / older_file_bak
bak.write_text(ori.read_text())
try:
with open(ori, 'r') as fi:
older = fi.read().splitlines()
req = urlopen("http://export.arxiv.org/rss/physics.ao-ph")
data = req.read()
tree = ElementTree.fromstring(data)
tags = ['title', 'description', 'link', 'creator']
toots = []
for child in tree:
_data = {}
if 'item' in child.tag:
for c in child:
for t in tags:
if t in c.tag:
_data[t] = c.text
toots.append(
Paper(
_data['title'],
_data['description'],
_data['link'],
_data['creator']
)
)
for toot in toots:
if toot.link not in older:
older.append(toot.link)
toot.toot()
with open(ori, 'w') as fo:
if len(older) > 50:
older = older[-50:]
for link in older:
fo.write(f'{link}\n')
bak.unlink()
print(f"Done!!! {dt.datetime.utcnow()}")
except:
ori.write_text(bak.read_text())
bak.unlink()
print(f"Something went wrong!!! {dt.datetime.utcnow()}")
Bien, vamos por partes y vamos explicando cada una de ellas.
Primero de todo importamos las bibliotecas que necesitamos. Como he comentado anteriormente, solo uso bibliotecas de la stdlib para que lo podamos usar en casi cualquier sitio que pueda ejecutar Python3 moderno.
from urllib.request import urlopen, Request
from dataclasses import dataclass
from xml.etree import ElementTree
import re
import json
from pathlib import Path
import datetime as dt
Lo siguiente que creamos es una dataclass llamada Paper que sirve para guardar la información que incluiremos en cada toot sobre cada uno de los nuevos artículos que encontremos en el RSS. Además, le he añadido una serie de métodos que sirve para limpiar un poco la información que se mostrará finalmente en el toot. El método toot final es el que enviará la información final con el formato obtenido a partir del resto de métodos a la API de Mastodon. Dentro del método toot está el host y el token. El host será específico de tu bot y tienes que cambiar esta url si tu cuenta de Mastodon está alojada en una instancia de Mastodon diferente a botsin.space. El token lo puedes obtener como se muestra más arriba.
@dataclass
class Paper:
title: str
description: str
link: str
creator: str
def _clean_title(self):
return self.title.split("(arXiv:")[0]
def _clean_description(self):
return self.description.replace("<p>", "").replace("</p>", "")
def _clean_creator(self):
reg_str = "<a href=.*?>(.*?)</a>"
res = re.findall(reg_str, self.creator)
return ", ".join(res)
def get_toot_text(self):
part1 = f"Title: {self._clean_title()}\n\n"
part3 = f"Authors: {self._clean_creator()}\n\n"
part4 = f"Link: {self.link}"
length = 500 - len(part1 + part3 + part4)
part2 = f"{self._clean_description()[:length - 8]} [...]\n\n"
toot_text = (part1 + part2 + part3 + part4)
return toot_text
def toot(self):
host = "https://botsin.space/api/v1/statuses"
token = "########TU_TOKEN########"
headers = {}
headers['Authorization'] = 'Bearer ' + token
headers["Content-Type"] = "application/json"
#headers = json.dumps(headers)
data = {}
data['status'] = self.get_toot_text()
data['visibility'] = 'public'
data = json.dumps(data).encode('utf-8')
req = Request(url=host, data=data, headers=headers)
resp = urlopen(req)
return resp.status
Además del bot tenemos que tener un fichero older.txt que puede ser un fichero vacio de primeras. El programa no creará el fichero older.txt por lo que este fichero debe existir. La siguiente parte del programa hará uso de este fichero. Aquí, lo unico que hacemos es generar las rutas al fichero older.txt y creamos un backup de este fichero (todo usando pathlib).:
older_file = 'older.txt'
older_file_bak = 'older.txt.bak'
ori = Path(__file__).parent.absolute() / older_file
bak = Path(__file__).parent.absolute() / older_file_bak
bak.write_text(ori.read_text())
En la siguiente porción de código es donde está la chicha. Abrimos el fichero older.txt y lo metemos en una variable llamada older. De primeras el fichero está vacio pero iremos metiendo los enlaces de arXiv de los nuevos artículos que vayamos tooteando. Luego pedimos el RSS de arXiv y lo leemos. La respuesta es un fichero xml y de ese fichero extraemos la información que nos interesa y creamos objetos Paper. Una vez que tenemos la información como objetos Paper usamos su método toot para ir creando un toot por cada uno de los artículos. Antes de tootear miramos si el link está contenido en older. Si está significará que ya lo hemos tooteado antes y evitamos el tootearlo de nuevo, es decir, solo generaremos toots de cosas que no hayamos tooteado previamente. Después de enviar los nuevos toots actualizamos la información de older.txt añadiendo los nuevos enlaces que acabamos de tootear (solo guardo los 50 últimos enlaces). Si todo ha funcionado correctamente elimino el backup del fichero older.txt que había creado al principio. Todo lo anterior está incluido en un try. Si falla algo pasamos al except donde deshacemos lo hecho y recuperamos el backup. Hay cosas que pueden fallar y no estoy contemplando algunas cosas que pueden haber ocurrido pero esto pretende ser solo un ejemplo.
try:
with open(ori, 'r') as fi:
older = fi.read().splitlines()
req = urlopen("http://export.arxiv.org/rss/physics.ao-ph")
data = req.read()
tree = ElementTree.fromstring(data)
tags = ['title', 'description', 'link', 'creator']
toots = []
for child in tree:
_data = {}
if 'item' in child.tag:
for c in child:
for t in tags:
if t in c.tag:
_data[t] = c.text
toots.append(
Paper(
_data['title'],
_data['description'],
_data['link'],
_data['creator']
)
)
for toot in toots:
if toot.link not in older:
older.append(toot.link)
toot.toot()
with open(ori, 'w') as fo:
if len(older) > 50:
older = older[-50:]
for link in older:
fo.write(f'{link}\n')
bak.unlink()
print(f"Done!!! {dt.datetime.utcnow()}")
except:
ori.write_text(bak.read_text())
bak.unlink()
print(f"Something went wrong!!! {dt.datetime.utcnow()}")
Y eso sería todo.
Si tienes interés, puedes seguir a nuestro nuevo bot aquí si tienes una cuenta en Mastodon. O, puedes subscribirte por rss usando este enlace.
Espero que a alguien le resulte útil. Y, recuerda, no hagas bots molestos.
Publicado originalmente en:
https://pybonacci.org/2021/06/09/como-hacer-un-bot-para-mastodon/